背景
使用Hexo完成博客搭建以后,为了分析用户感兴趣的文章以及对用户看文章的路径进行分析,决定对网站进行埋点。
通过对埋点获得的数据,基于用户行为数据构造用户画像。对用户的访问过程进行记录并实时传输到serverless日志服务器。基于用户访问博客文章的路径、每篇文章的停留时间、用户来源地等数据实现对用户进行分类以及筛选文章受众程度。如下图所示,系统记录了用户以下数据: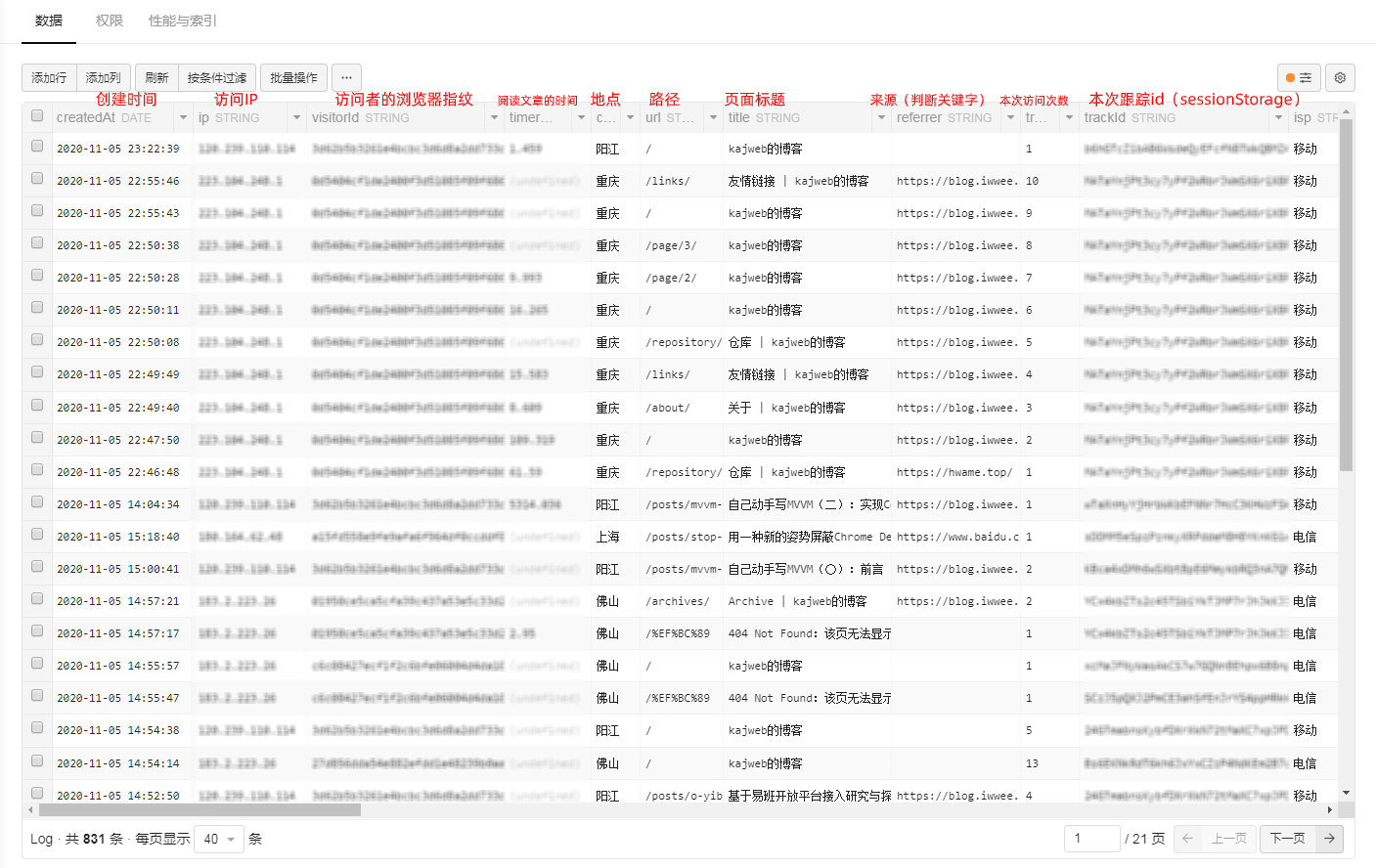
- 访问页面的时间
- 访问页面的IP
- 访问者的浏览器指纹
- 页面的浏览时间
- IP来源地
- 访问的路径
- 页面的标题
- 页面的来源
- 单次用户访问网页的数量
- 单次跟踪Id
使用到的服务
| name | use |
|---|---|
| LeanCloud | serverless云函数服务,用于接收track请求 |
| 数据存储服务 | 使用LeanCloud提供的数据存储服务 |
| FingerprintJS | 用于生成浏览器指纹 |
| sessionStorage | 单次追踪标志与用户行为顺序记录器 |
基本原理
初始化跟踪器
- 在用户访问网页的时,首先从sessionStorage读取
blogTrackId的值。 - 如果读取成功,代表用户非首次进入博客。
blogTrack访问计数器加1。 - 如果读取失败,代表用户首次进入网站。使用随机数构造器
randomString(len)生成一个32位的随机数。将该随机数储存为blogTrackId。
blogTrackId理论上应当由server进行查询并计算。
由于本博客访问人数较少,同时为了减少对数据存储查询次数,所以直接由前端生成并计算。
用户行为跟踪
在初始化跟踪器后,已经得到本次访问网页的跟踪IdblogTrackId和单次访问次数blogTrack。blogTrackId的生命周期是当前页面,也就是说页面关闭时blogTrackId将被销毁。
由于http协议是无状态的,服务端无法感知并匹配用户端,此时还无法感知访问者历史访问状态。 这时候需要让用户本次访问与历史访问关联起来,所以需要使用浏览器跟踪技术。
本次跟踪使用FingerprintJS快速浏览器指纹库技术,通过浏览器的特征生成浏览器指纹visitorId。在浏览器环境不发生改变时,相应的浏览器指纹也不变化,可以达到关闭浏览器、清空浏览器缓存后浏览器指纹唯一的目的。
通过这个唯一的指纹,后台对数据进行分析是可以基于visitorId和blogTrackId一对多个的关系进行匹配。在用户访问网页时,会发生以下情况:
- 同一个(出口)IP使用不同的浏览器时,IP不变,
visitorId匹配相应的浏览器。 - 同一个浏览器在不同的上下文打开博客时,
visitorId不变,blogTrack依赖首次打开页面生成,并在关闭页面时销毁。
文章停留时间计数器
本次用户行为分析主要是记录用户在博客的行为分析,所以用户在页面的停留时间与对文章的喜爱程度具有很大的关联性。用户离开页面的行为主要有以下两种情况:
- 通过点击链接打开新文章,并关闭当前页面
- 用户通过(浏览器)关闭按钮关闭页面
- 用户通过浏览器的返回按钮返回到上一页
不同的浏览器对于上述三种情况处理会稍有不同:
- 对于前面前两种情况,在PC端和移动端都可以很好的触发
onbeforeunload()事件; - 对于第三种情况用户使用
返回按钮返回上一页,在PC端可以重新加载页面,重新对页面进行Init初始化操作,但是在移动端(UC浏览器)会缓存页面,页面栈中未对跳转前页面进行销毁。针对这种情况,需要使用window.onpageshow()事件监听页面显示,对于缓存页面的跟踪器进行重新初始化操作。
注意,在
onbeforeunload()里面如果需要进行XHR操作,必须发送同步Ajax请求。对于异步Ajax请求有可能导致浏览器与服务端握手未完成的时候关闭页面,导致数据同步失败。
本次文章停留时间计数器基于
通过IP获得地址信息
在serverless中,我们可以通过request.params.ip获得访问者的IP,但是为了在数据报表中更好的提现访问者的来源,往往会对访问的的ip信息进行解析。
本次使用的是淘宝IP地址库,通过request模块请求API以及内部的accessKey:ali*****inc进行IP地址信息查询。
淘宝IP地址库在某一次升级以后,升级迁移到阿里云官方“IP地理位置库”。
原来的淘宝ip地址库需要书面同意后才能对接。

